install.packages('tuber')
library(tuber)Tuber - connecting R to Youtube API
R
tuber
Youtube
webscraping
How to use tuber to scrap data from Youtube
This is my first post related to R. Currently, I am working on a project focused on analyzing the comments from a series of videos featuring “SúperBigote” from the Venezuelan National TV’s, on a parritular YouTube channel (at a later date I will delve on the nature and origin of this channel).
Since these videos can be classified as political propaganda, my objective is to conduct sentiment analysis and explore the words and expressions associated with each video. To begin this analysis, my initial step would involve scraping all the comments and associated data, such as likes and comments on comments, for further examination.
After some search online I found out the “tuber” package. The R package “tuber” is a powerful tool for accessing and analyzing YouTube data directly within the R programming environment. Developed to simplify the process of extracting information from YouTube’s extensive collection of videos, channels, and playlists, tuber provides a comprehensive set of functions and features. With tuber, users can effortlessly retrieve video metadata, including title, description, view count, and upload date, as well as gather detailed statistics on channels and playlists. Additionally, tuber offers functionalities for searching videos, accessing comments, and even downloading video content. Its intuitive and user-friendly design makes it accessible to both beginners and experienced data scientists, making it an essential package for anyone interested in leveraging YouTube data for research, analysis, or content creation purposes.
Due to the necessity of integrating with the YouTube API and the challenges I faced in finding up-to-date, comprehensive instructions online, I have decided to create this post. In doing so, I aim to provide a step-by-step guide that addresses the difficulties I encountered, ensuring a smoother integration process for others who may be facing similar obstacles.
So the first step is installing the tuber package and loading the library:
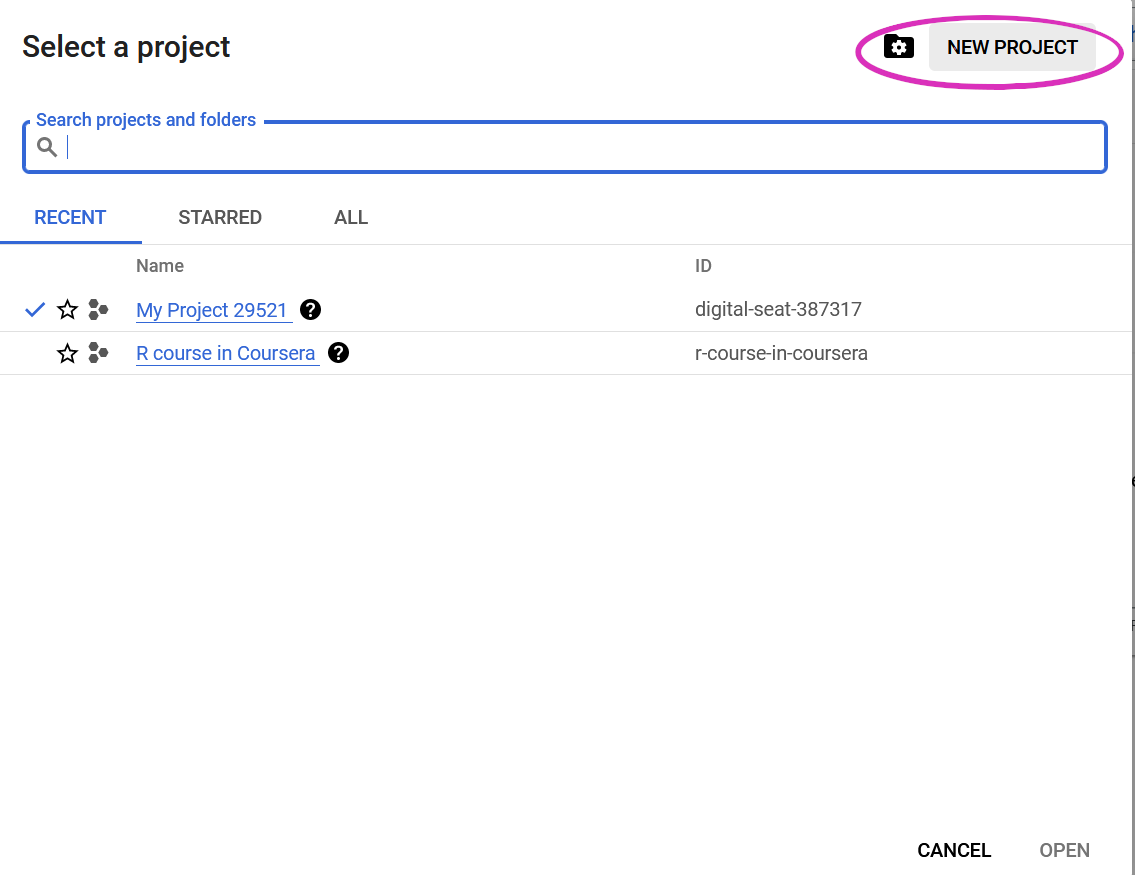
Next you will need to go the Google APIs dashboard and create a new project. I already had my Google APIs account active from a previous project, so there might be an extra step here if you haven’t one already.
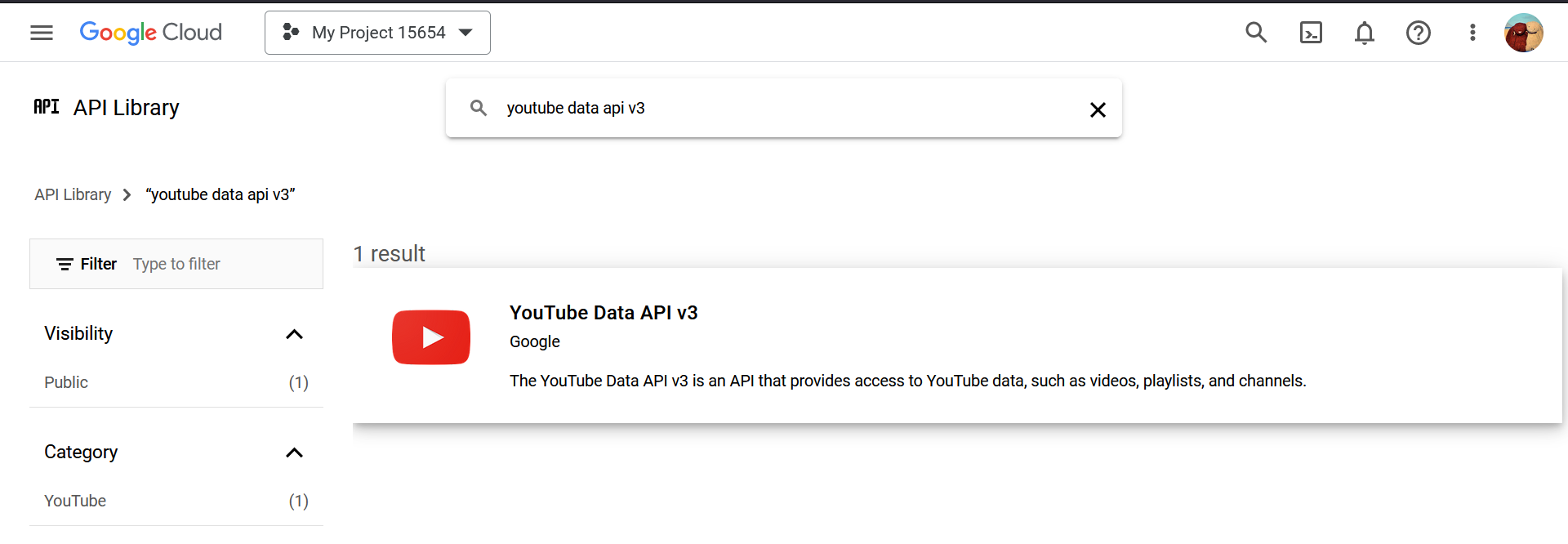
Then, enable APIs and Services. -> search for YouTube Data API v3 and enable that one.
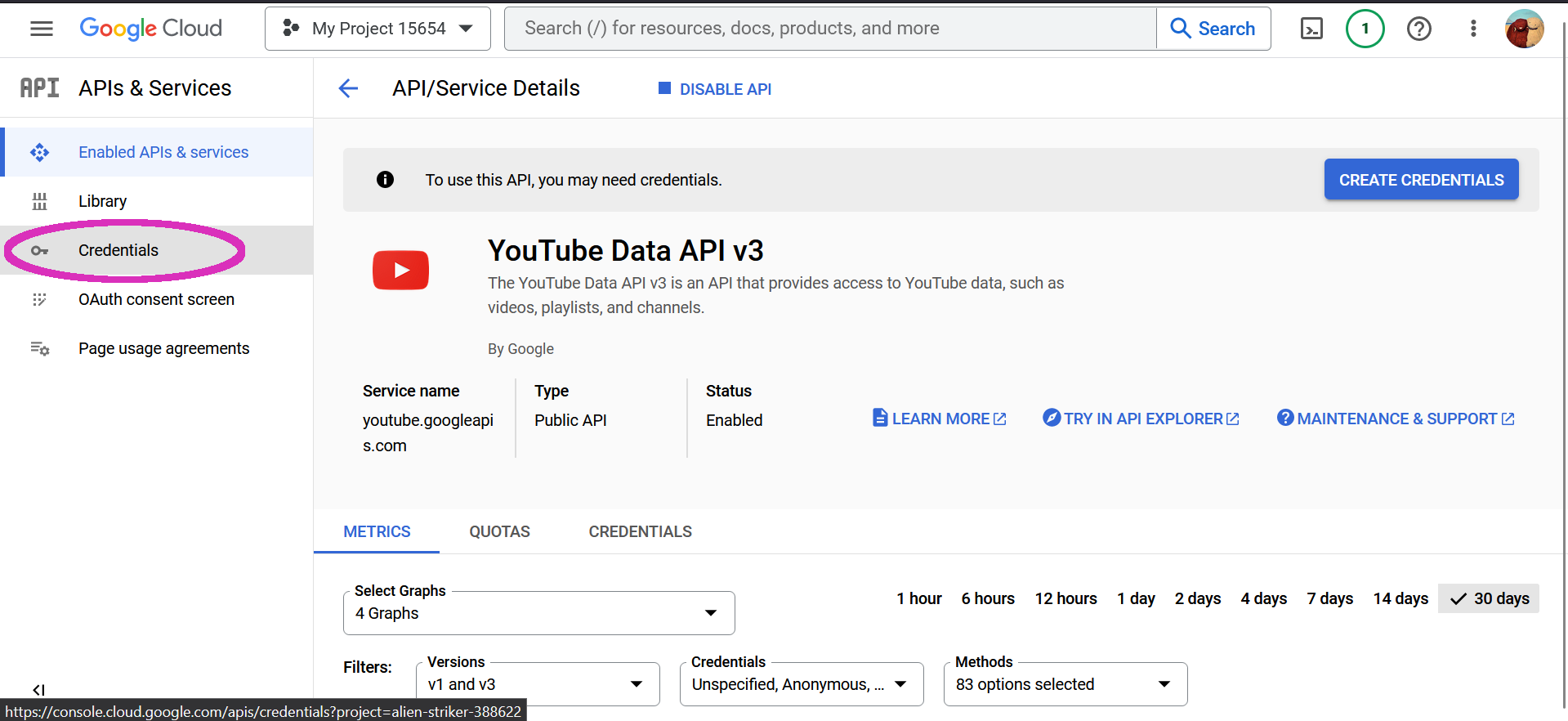
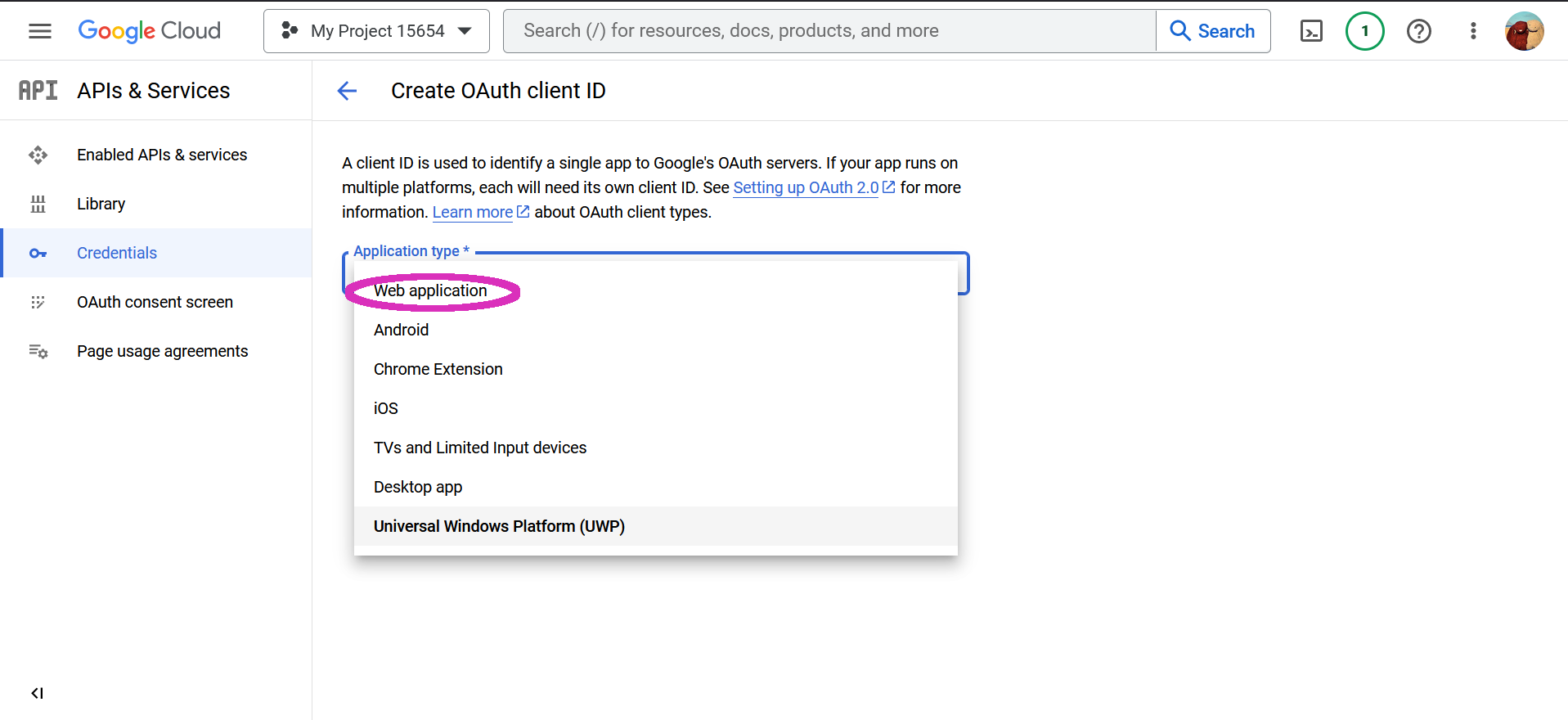
Next, create credentials. -> You need to choose OAuth Client ID.
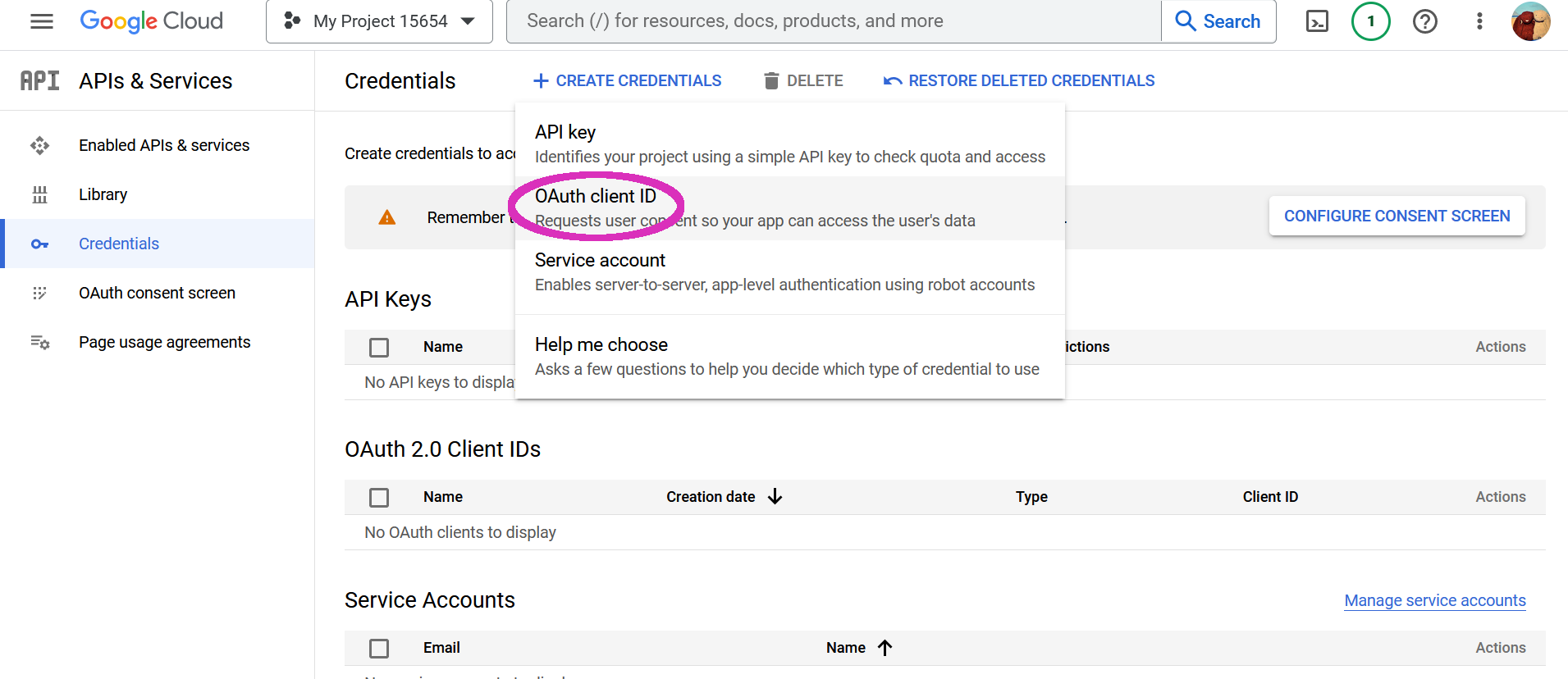
For that you will need to first setup the consent screen. Afterwards create the OAuth Client ID. Here you need to chose the Web application.
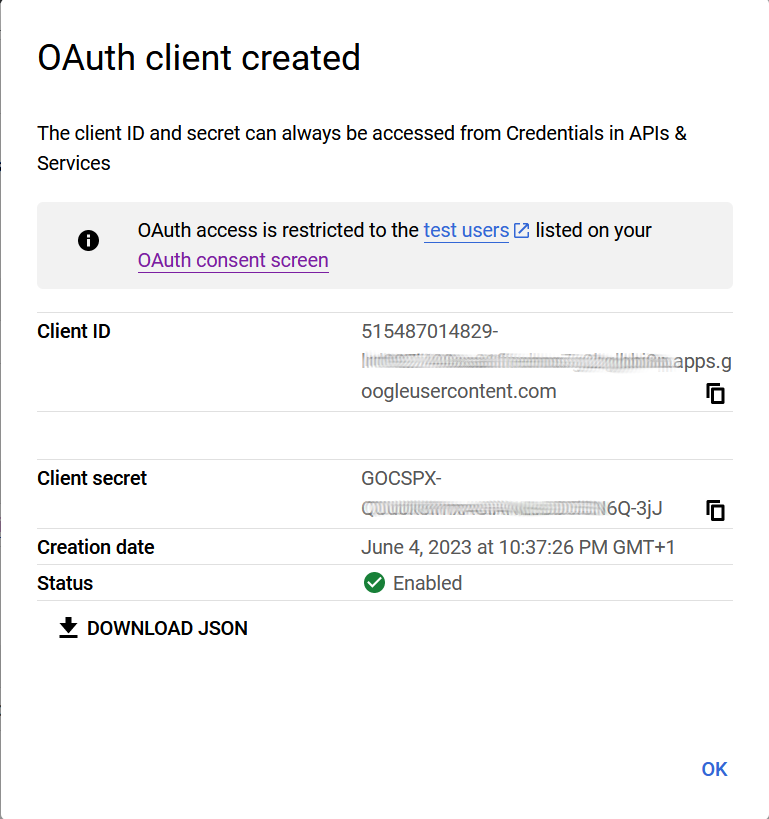
Once the you done this, you have finished. Now you need to take note of the ClientID and the Secret, and to download the Json to your working directory.
In R you code should look like this:
library(tuber)
library(tidyverse)
id <- '108XXXXXXXXX-myidAAAAAAAA.apps.googleusercontent.com'
secret <- 'GOCSPX-wrMYSECRETXXXXXXXXXX'
yt_oauth(id, secret, token = '')Once you’ve run the yt_oauth() command, you will authenticate the application and R will download a “.httr-oauth” file, and then tuber you connected to youtube and you can use all its functions. Namely the get_all_comments() to download all comments. Which later you can place it in a data-frame, and do data wrangling as needed.
From session to session you need to reauthenticate the application by running the yt_oauth(). If you already have the “.httr-oauth” file on your working directory, this wont work. So to get around this, I added this piece of code at the beginning of my script.
if (file.exists('.httr-oauth')) {
file.remove('.httr-oauth')
}This post marks the beginning of a series where I will delve into the analysis process. A significant challenge I face is that the majority of comments are in Spanish, rendering standard sentiment analysis packages ineffective. Therefore, my next hurdle will involve exploring alternative solutions, such as finding a suitable sentiment analysis package or utilizing a machine learning model capable of classifying the vast number of comments. Alternatively, I might resort to manually classifying approximately 6000 comments. Regardless, this presents an intriguing challenge that I am prepared to tackle in the upcoming stages.
Citation
BibTeX citation:
@online{granja-correia2023,
author = {Granja-Correia, João},
title = {Tuber - Connecting {R} to {Youtube} {API}},
date = {2023-06-05},
url = {https://joao.granja-correia.eu/blog/blog_20230603_Tuber/},
langid = {en}
}
For attribution, please cite this work as:
Granja-Correia, João. 2023. “Tuber - Connecting R to Youtube
API.” June 5, 2023. https://joao.granja-correia.eu/blog/blog_20230603_Tuber/.